Get Premium
Dark mode theme is available exclusively for premium users. Learn more about the benefits of subscribing.
No fees, cancel anytime.

 Dark Mode Ad-Free Browsing Unlimited Content
Dark Mode Ad-Free Browsing Unlimited Content 
 Ad-Free Browsing Unlimited Content Dark Mode
Ad-Free Browsing Unlimited Content Dark Mode 
Join 1.2 million Panda readers who get the best art, memes, and fun stories every week!

With smart technologies improving so fast, it seems that we have no time left to stop and think about whether this progress is useful or toxic for our society. Recently, many people have shown their concern about the “deepfakes” that have been surfacing across the Internet. Simply put, deepfakes provide a possibility to put a face on another person in a video, which gives a lot of opportunities to create illegal fake content without a person’s consent. Now, this AI technology has improved even more, and it’s amazing yet scary at the same time.
More info: Egor Zakharov
They have created what can be called “living portraits,” and all they need is a single picture that they can turn into a fake video.
This discovery is called a few-shot, and one-shot learning and all it needs is a single image to turn it into an animated portrait. If a few more shots are provided, the result is even more striking.
In their recent paper, researchers explained their goals and reasons why they are creating this artificial intelligence technology: “Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. To create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present the newest technology with such few-shot capability.”
“It performs lengthy meta-learning on a large dataset of videos, and after that can frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators.”
“Crucially, the system can initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach can learn highly realistic and personalized talking head models of new people and even portrait paintings.”
In the deepfake maker video, the researchers show that the larger the number of photos from different angles provided, the more realistic the result
“Currently, the key limitations of our method are the mimics representation (in particular, the current set of landmarks does not represent the gaze in any way) and the lack of landmark adaptation. Using landmarks from a different person leads to a noticeable personality mismatch. So, if one wants to create “fake” puppeteering videos without such mismatch, some landmark adaptation is needed,” the developers added in their paper while talking about artificial intelligence future.
30Kviews
Share on Facebook
Yeah, although interesting, I can see the problems. Especially legal ones, where video can no longer be used as evidence, and it will further push people who decry everything as "fake news" to dig their heels in deeper. And, as someone above said, bad people can brush off authentic video as "fake" because any video can be faked...
Was thinking the same thing, Ben. Sometimes advancement in technology is not a good thing lol
Load More Replies...You will see ordinary people pictures would be converted into adverts by any prankster or sx industry. *sigh*
Load More Replies...Yeah, although interesting, I can see the problems. Especially legal ones, where video can no longer be used as evidence, and it will further push people who decry everything as "fake news" to dig their heels in deeper. And, as someone above said, bad people can brush off authentic video as "fake" because any video can be faked...
Was thinking the same thing, Ben. Sometimes advancement in technology is not a good thing lol
Load More Replies...You will see ordinary people pictures would be converted into adverts by any prankster or sx industry. *sigh*
Load More Replies...










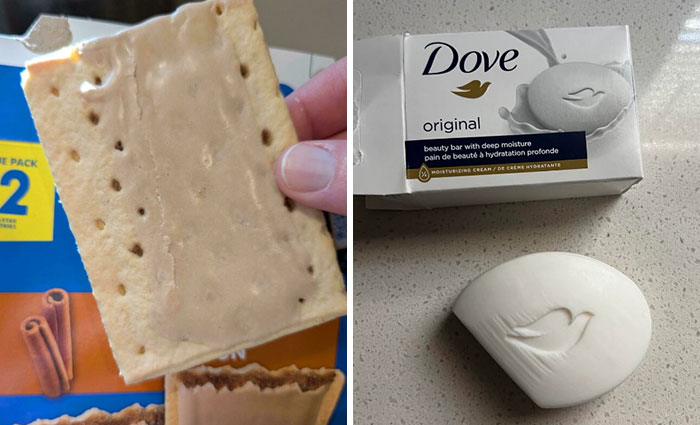



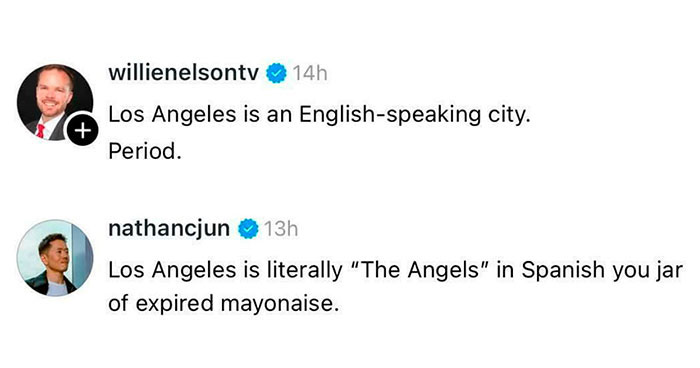




















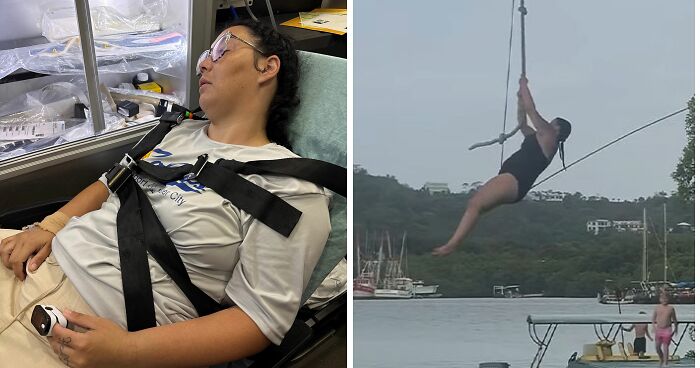


 No fees, cancel anytime
No fees, cancel anytime 






















101
23